Monday, October 22, 2012
Java to Python Cheatsheet
Null -> None
array -> list
hash -> dictionary or collections.Counter
method -> methods (attached to classes) and functions (detached from classes)
casting -> coercion
overloading -> no overloading
http://pypi.python.org/pypi - python packages
http://docs.python.org
http://www.pythontutor.com/
import time
import sys
import datetime
import collections
Thursday, August 23, 2012
Grails vs. Ruby on Rails
Are you at the point when you need to decide what will be your next Rapid Application Development framework for your new website? You heard a lot about Ruby on Rails, right? It's soooo cool and sexy and stuff!
But wait, look at that Grails, Ruby on Rails:

Hugely popular in the past ROR (Ruby on Rails) is giving in to Grails. I think the reasons are the following:
But wait, look at that Grails, Ruby on Rails:

Hugely popular in the past ROR (Ruby on Rails) is giving in to Grails. I think the reasons are the following:
- Performance, performance, performance. Twitter is dumping ROR because of performance. Grails, on the other hand, is compiled into Java and runs in a JVM.
- More and more Java developers discover Grails.
- I can't think of anything else right now :)
Thursday, June 21, 2012
Hive CREATE TABLE AS SELECT Hadoop CTAS
When you search for CREATE TABLE AS SELECT in Hive you end up with documentation that simply doesn't give a simple example but rather shows complex examples that dig too dip but don't explain how to do it quickly. And here is the simple example:
CREATE TABLE T2 AS SELECT * FROM T1 WHERE C1 LIKE 'something%';
It works, I've just tried it.
==============================
Later addition. It works on a limited data. If your source table is huge then it's going to be a problem. The main problem is that this query allocates only one reducer by default. So you have two choices - either increase number of reducers or do the following:
CREATE TABLE T2 AS SELECT * FROM T1 WHERE C1 LIKE 'something%';
It works, I've just tried it.
==============================
Later addition. It works on a limited data. If your source table is huge then it's going to be a problem. The main problem is that this query allocates only one reducer by default. So you have two choices - either increase number of reducers or do the following:
- Copy a sample file to your directory
- Create a new table based on this file
Hadoop Hive SPLIT example
For example you have a table that tracks your visitors and you want to see who was the top referers but you don't want to see anything after the "?", i.e. to remove the http parameters:
select split(referer, '\\?')[0], count(*) as cnt from event_log where referer is not null group by split(referer, '\\?')[0] order by cnt desc limit 100;
Note that we need to escape the ? because it's a special symbol in regular expressions. So if you have the following input
http://www.a.com/something?param1=yes¶m2=no
http://www.b.com/hehe?submit=true
then the output will be
http://www.a.com/something 1
http://www.b.com/hehe 1
select split(referer, '\\?')[0], count(*) as cnt from event_log where referer is not null group by split(referer, '\\?')[0] order by cnt desc limit 100;
Note that we need to escape the ? because it's a special symbol in regular expressions. So if you have the following input
http://www.a.com/something?param1=yes¶m2=no
http://www.b.com/hehe?submit=true
then the output will be
http://www.a.com/something 1
http://www.b.com/hehe 1
Wednesday, June 20, 2012
NOT LIKE Function in Hadoop Hive
In SQL usually the query is the following:
In Hive this doesn't work. Instead do the following:
select * from table_name where column_name not like '%something%';
In Hive this doesn't work. Instead do the following:
select * from table_name where not (column_name like '%something%');
Thursday, June 14, 2012
SenchaTouch is slow to load as a mobile web app
The mobile web application for Internet Polyglot http://m.internetpolyglot.com (doesn't work in Firefox since it doesn't support WebKit) has been deployed to production a couple of months ago and shows very poor results in terms of user bounce rate. Too many users are dropping off almost immediately.
The application is written in SenchaTouch. There had been many thoughts about what framework to use for this app at the time. First idea was that it must be HTML5 as opposed to a native iOS or Android app - for the purpose of single code base. Then a decision was made in favor of SenchaTouch before jQueryMobile because anekdotally SenchaTouch was more powerful as a app development platform. And wrapped in PhoneGap it would serve also as a deployable app on Apple Appstore and Android Market.
But the problem is the loading speed. When I open the app in my iPhone's browser it takes too long time to show even the splash screen. I suppose it loads SenchaTouch libraries first and they are big. Maybe SenchaTouch cannot be used for mobile web apps? Maybe it's only for development of PhoneGap'd apps?
Recently the app was rewritten in SenchaTouch 2 but I don't see much of loading speed improvement.
If anybody knows how to speed up the loading of an app written in SenchaTouch - please comment.
The application is written in SenchaTouch. There had been many thoughts about what framework to use for this app at the time. First idea was that it must be HTML5 as opposed to a native iOS or Android app - for the purpose of single code base. Then a decision was made in favor of SenchaTouch before jQueryMobile because anekdotally SenchaTouch was more powerful as a app development platform. And wrapped in PhoneGap it would serve also as a deployable app on Apple Appstore and Android Market.
But the problem is the loading speed. When I open the app in my iPhone's browser it takes too long time to show even the splash screen. I suppose it loads SenchaTouch libraries first and they are big. Maybe SenchaTouch cannot be used for mobile web apps? Maybe it's only for development of PhoneGap'd apps?
Recently the app was rewritten in SenchaTouch 2 but I don't see much of loading speed improvement.
If anybody knows how to speed up the loading of an app written in SenchaTouch - please comment.
Hadoop Summit Day 2
The second day of Hadoop Summit.

You can grow and shrink a single VM to accommodate the load:

It's hard to add and remove the nodes because of losing the state - this is a problem.
And the big idea is to keep HDFS on physical hosts and place the MapReduce nodes in VMs - in this case the state is not lost and task nodes can be added/removed at will.





As I mentioned before there are only few places where you can charge your laptop. And the Macbook is always hungry...
.JPG)
Solution: Partition Incremental Discretization (PiD). Which give an approximate histogram.





pic 1
Elastic MapReduce jobs run on a cluster or clusters.

pic 2
It can be provisioned to 1000 MapReduce instances in 5 minutes.
You can have lots of clusters.
Instead HDFS the data is read from S3. S3 is more durable - 11 9's of durability and 99.9% availability.
Why HDFS is faster for scanning, so it's better to use hdfs like a cache for temporary data while keeping permanent data in S3.

pic 3
Also S3 can be used for migrating HDFS clusters from older version to new version

pic 4
Steps and Bootstrap actions
Steps are MapReduce tasks or can be Hive or Pig scripts. They are stored in S3

pic 5
BootStrap actions are running in the beginning of each workflow. The are also stored in S3

pic 6
Complex Workflows can be written in scripting languages like python. Alternatively AWS Flow Framework can be used (it seems this is something like cascading)
There are development, testing and production stacks. You can develop your hadoop programs in isolation and point to different S3 storages.
 pic 7
pic 7
Validating Computations technique. Do computations twice using different logic to test correctness of the main logic.
 pic 8
pic 8
Performance tuning is achieved surprisingly by switching from one instance type to another with different memory and disk capacity:
 pic 9
pic 9
There are different models of payment for computing power:
 pic 10
pic 10
Review:
.JPG)
pic 11
MOOCs (massive open source courses)
In Hadoop we can store:
.JPG)
== VMWare: Apache Hadoop and Virtual Machines
The idea is to place multiple Virtual Machines on cluster's machines and place Hadoop nodes on those VMs.
You can grow and shrink a single VM to accommodate the load:

It's hard to add and remove the nodes because of losing the state - this is a problem.
And the big idea is to keep HDFS on physical hosts and place the MapReduce nodes in VMs - in this case the state is not lost and task nodes can be added/removed at will.


== Analytical Queries with Hive: SQL Windowing and Table Functions
Amazingly uninteresting session - the presenter didn't talk about high level problem statement but gave too much internal implementations. Or maybe I am just not qualified enough to understand it. Anyway there are a couple of screenshots:


== Starving for Juice (intermission)
As I mentioned before there are only few places where you can charge your laptop. And the Macbook is always hungry...
.JPG)
== Creating Histograms from a Data Stream via MapReduce
The problem is that the data comes as a stream, it's hard to get min and max. And the data is distributed.Solution: Partition Incremental Discretization (PiD). Which give an approximate histogram.




== Hadoop Best Practices in the Cloud
The presenter was previously at Amazon so he presents AWS.
pic 1
Elastic MapReduce jobs run on a cluster or clusters.

pic 2
It can be provisioned to 1000 MapReduce instances in 5 minutes.
You can have lots of clusters.
Instead HDFS the data is read from S3. S3 is more durable - 11 9's of durability and 99.9% availability.
Why HDFS is faster for scanning, so it's better to use hdfs like a cache for temporary data while keeping permanent data in S3.

pic 3
Also S3 can be used for migrating HDFS clusters from older version to new version

pic 4
Steps and Bootstrap actions
Steps are MapReduce tasks or can be Hive or Pig scripts. They are stored in S3

pic 5
BootStrap actions are running in the beginning of each workflow. The are also stored in S3

pic 6
Complex Workflows can be written in scripting languages like python. Alternatively AWS Flow Framework can be used (it seems this is something like cascading)
There are development, testing and production stacks. You can develop your hadoop programs in isolation and point to different S3 storages.

Validating Computations technique. Do computations twice using different logic to test correctness of the main logic.

Performance tuning is achieved surprisingly by switching from one instance type to another with different memory and disk capacity:

There are different models of payment for computing power:
- on demand
- spot marked
- reserved instances

Review:
.JPG)
pic 11
== Hadoop in Education
MOOCs (massive open source courses)
In Hadoop we can store:
- Student logs
- Student Assessments
- Faculty interaction logs
- Student/Faculty interaction logs
- Processed Content Usage
Challenges:
- Client-generated logs (i.e. logs from GWT/javaSCript)
- Those logs must be provided w/o much of developers effort
- How to feed this data to Hive
- How to sessionize this data
Technical solution:
.JPG)
Technical challenges:
- Joins of big data
Wednesday, June 13, 2012
Hadoop Summit San Jose June 13-14, 2012
Hadoop Summit is taking place in San Jose, California in June 13 and 14. There are different interesting and not so interesting sessions.
An observation about organization - so many things are distributed, in the spirit of Hadoop distributed nature. Examples - one big hall for lunch and presenters' booths is in one end of the building, the sessions are in the other end of the building - so people have to walk there and back. Another example - lunch: boxes with sandwiches on one side of the hall, soda is on the other...
There are no power sockets to plug your laptop. Only a couple of them along the walls.
Several sessions are over-capacitated. Couldn't get to some of the sessions.
But anyway here are some session notes:
Another climate prediction company:
Case study airbnb (find a place to stay) - they moved from RDS to DinamoDB (Amazon nosql db)
and use S3 for data storage
Different data:

Aster SQL-H - for business people

.NET also has a neat way to programmatically submit the Hive jobs.
JavaScript can call Hadoop jobs from "Interactive JavaScript console" in hadooponazure.com. You can query hive and parse the results into json and then graph it.
Hadoop you do? I am fine... -- funny sentence.
Overall: Microsoft did a good job in bringing Hadoop to the less technically prepared people.


An observation about organization - so many things are distributed, in the spirit of Hadoop distributed nature. Examples - one big hall for lunch and presenters' booths is in one end of the building, the sessions are in the other end of the building - so people have to walk there and back. Another example - lunch: boxes with sandwiches on one side of the hall, soda is on the other...
There are no power sockets to plug your laptop. Only a couple of them along the walls.
Several sessions are over-capacitated. Couldn't get to some of the sessions.
But anyway here are some session notes:
Hadoop sessions notes
== AWS (Amazon Web Services) big data infrastructure
- Netflix streams data from S3 directly into MapReduce (w/o HDFS) and back
- Netflix bumps up from 300 to 400+ nodes over weekend
- Netflix has an additional query cluster
- Cheaper Experimentation = Faster Innovation
- Logs are stored as JSON in S3
- Honu a tool that aggregates logs and makes it available as Hive tables for analysts https://github.com/jboulon/Honu
Another climate prediction company:
- Provision a cluster, send data, run jobs, shut down the cluster.
Case study airbnb (find a place to stay) - they moved from RDS to DinamoDB (Amazon nosql db)
and use S3 for data storage
== Unified Big Data Architecture: Integrating Hadoop within an Enterprise Analytical Ecosystem - Aster
Different data:
- stable schema (structured) - data from RDB's, ... Use Teradata or Hadoop sometimes
- evolving schema (semi-structured) - web logs, twitter stream, ... Hadoop, Aster for joining with structured data and for SQL+MapReduce
- no schema (unstructured), PDF files, images,... Hadoop, sometimes Aster for MapReduce Analytics

Aster SQL-H - for business people
- ANSI SQL on Hadoop data
- through HCatalog it connects to Hive and HDFS

== Scalding (new Hadoop language from Twitter)
- it looked to me as a library for Scala and Cascading
- it can read/write from/to HDFS, DBs, MemCache, etc...
- the model is similar to Pig and coding style is similar to Cascading
- you can develop locally without shipping to hadoop
- I was loosing track actually when the guy was talking about scala or cascading or scalding because of lack of my knowledge in these things
- scala is a language for writing, not reading (personal impression)
== Microsoft Big Data
- Microsoft wants to make sure that Hadoop works well on Azur as well as Windows
- On Azur it has neat UI for administration and data processing
- It has Hive console to create and manage Hive tables
- It's all on http://hadooponazure.com
- Integrating Excel to hadooponazure. You download an odbc driver for Hive and connect your Excel to Hive data.
- Then can you can build Hive data and pull data to excel. Then this excel doc is uploaded to SharePoint where do all sorts of reporting, pivoting and charting. Once you republish this document to the SharePoint then you can schedule this excel document to refresh itself from hadoop with a certain cadency.
.NET also has a neat way to programmatically submit the Hive jobs.
JavaScript can call Hadoop jobs from "Interactive JavaScript console" in hadooponazure.com. You can query hive and parse the results into json and then graph it.
Hadoop you do? I am fine... -- funny sentence.
Overall: Microsoft did a good job in bringing Hadoop to the less technically prepared people.
== Hadoop and Cloud @ Netflix
- They recommend movies based on Facebook (user's profile, friends)
- Everything is personalized
- 25M+ subscribers
- 4M/day ratings
- Searches: 3M/day
- Plays: 30M/day
They use
- Hadoop
- Hive
- Pig
- Java
They use "Markov Chains" algorithm.

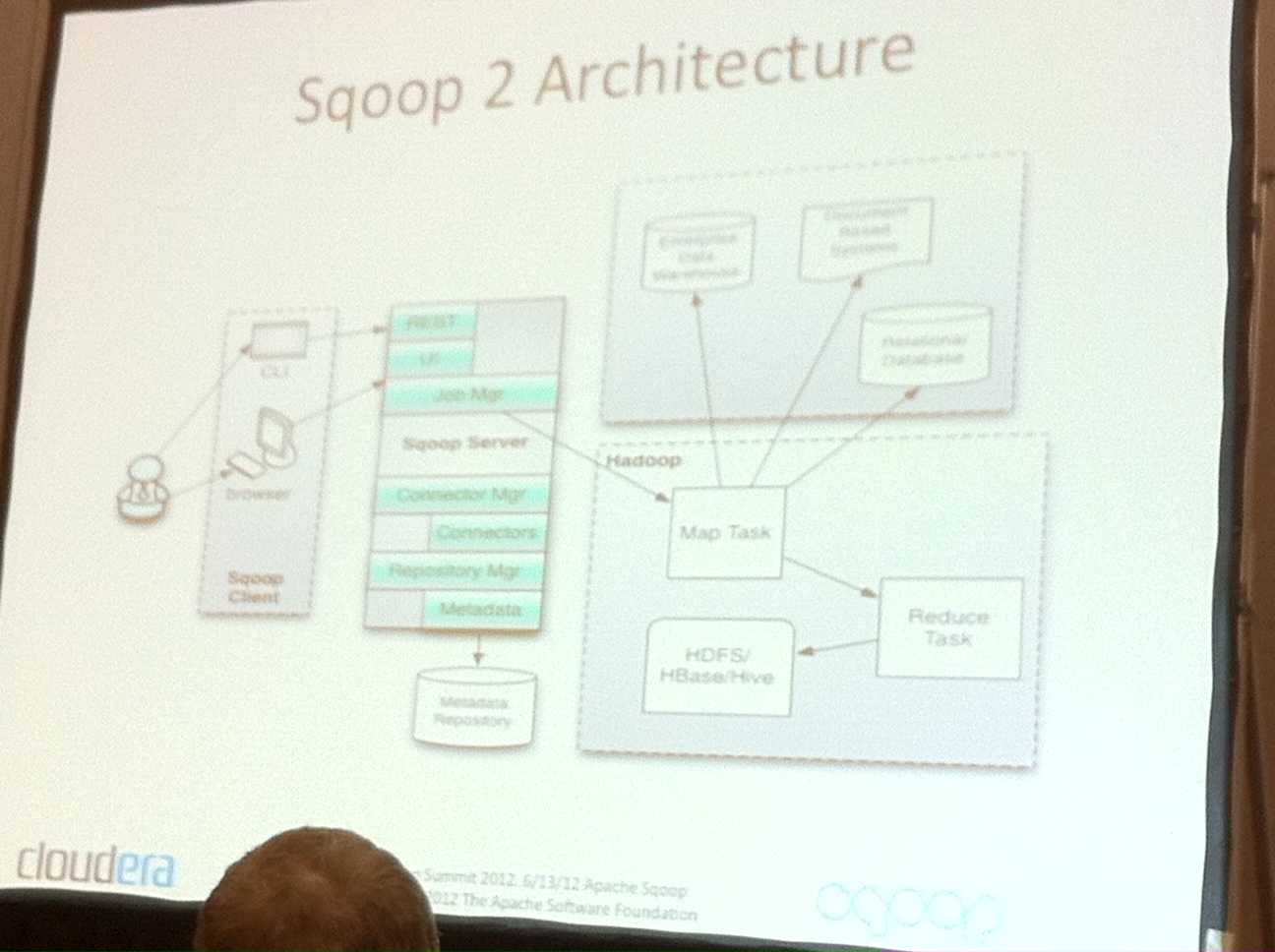
Sqoop 2
- It's moving data from/to relational and non-relational databases
- It's much easier to use than sqoop 1
- It has UI admin panel
- It's now client-server as opposed to only client sqoop 1
- It's easier to integrate with Hive and HBase. In fact you can not only move data from db's to hdfs but also further move data to hive tables or hbase tables
- It is going to be more secure
Tuesday, February 21, 2012
Could not get Chrome DLL version RelaunchChromeBrowserWithNewCommandLineIfNeeded
This error can occur in many circumstances. In my case I was running chrome.exe from command line to pack Chrome extension. But searching internet shows that this error occurs in many different environments and circumstances. What worked for me:
- Go to the Chrome installation directory C:\Users\yourusername\AppData\Local\Google\Chrome\Application
- It has the following directory inside: "17.0.963.56" - the name of directory on your computer can be different
- Simply add the full path to the chrome home directory and this build directory to your "PATH" environment variable.
Git to Hudson: Please tell me who you are
Here is the error that Git gives Hudson sometimes:
And here is the solution:
Caused by: hudson.plugins.git.GitException: Error performing command: git.exe tag -a -f -m Hudson Build #4 hudson-seo-plugin-4
Command "git.exe tag -a -f -m Hudson Build #4 hudson-seo-plugin-4" returned status code 128:
*** Please tell me who you are.
Run
git config --global user.email "you@example.com"
git config --global user.name "Your Name"
to set your account's default identity.
Omit --global to set the identity only in this repository.And here is the solution:
- Go to your project
- Click Configure
- Under "Source Code Management" -> Git click on "Advanced" button
- Enter required data in "Config user.name Value" and "Config user.email Value"
- Click "Save" at the bottom of the page.
- Restart you build by clicking "Build Now"
Wednesday, February 08, 2012
Photoshop Transparent Background in CS5
I was trying to remove background from a couple of icons. Internet is full of articles that tell you to use the Magic Wand then press Delete. I did it but instead of deleting the background it would show me the following dialog:

and whatever I did - changed Contents or Blending, changed Opacity - nothing helped. I simply cannot delete the background!
After an hour of agony I decided to try another tool - Background Eraser Tool and when I was opening it I accidentally noticed another tool - Magic Eraser Tool. Select it and click on your background - it's going to work.
and whatever I did - changed Contents or Blending, changed Opacity - nothing helped. I simply cannot delete the background!
After an hour of agony I decided to try another tool - Background Eraser Tool and when I was opening it I accidentally noticed another tool - Magic Eraser Tool. Select it and click on your background - it's going to work.
Subscribe to:
Comments (Atom)